


History and Basic of AI
🔹 The Problem:
জার্মান সেনারা তখন ব্যবহার করত একটি অতি জটিল **“Enigma Machine”**, যা প্রতিদিন বার্তা এনক্রিপ্ট (গোপন কোডে) করে পাঠাত।
এমনভাবে কোড বদলানো হতো যে কেউই সহজে বার্তা ভাঙতে পারত না।
🔹1. Turing’s Contribution:
ইংল্যান্ডের এক young mathematician ছিলেন Alan Turing, বললেন — “যদি এমন একটা machine বানানো যায়, যা মানুষের মতো চিন্তা করে কোড ভাঙতে পারে?”
তিনি তৈরি করলেন **“Bombe Machine”**, যা mathematical logic দিয়ে Enigma কোড ভাঙতে সক্ষম হয়।
💡 এই ঘটনা থেকেই **machine intelligence** এর ধারণা জন্ম নেয়।
→ এখান থেকেই **Modern Computer এবং Artificial Intelligence(AI)** ধারণার শুরু।
💬 2. Turing Test (1950)
যুদ্ধ শেষ হওয়ার পর Turing এক নতুন প্রশ্ন তুললেন —
**“Can machines think?”**
তিনি প্রস্তাব করলেন **Turing Test**:
যদি কোনো মেশিন মানুষের মতো কথা বলতে পারে, এমনভাবে যে একজন মানুষ বুঝতে না পারে কে মেশিন আর কে মানুষ — তাহলে মেশিনটি **intelligent** বলা যাবে।
👉 এই ভাবনা থেকেই **AI research** শুরু হলো।
💻 3. Mark 1 Machines – The Beginning of Computers
1940-50 এর দশকে প্রথমদিকের computer systems তৈরি হয় — যেমন **Mark I**, **ENIAC**, **UNIVAC** ইত্যাদি।
এগুলো ছিল বিশাল আকারের, হাজার হাজার vacuum tube দিয়ে বানানো। এই মেশিনগুলো শুধু হিসাব করত, কিন্তু নিজে ভাবতে পারত না। তবুও এগুলোই modern AI এর বীজ রোপণ করল।
🌱 4. 1956 – The Birth of the Term “Artificial Intelligence”
AI শব্দটির জন্ম হয় **1956 সালে**, **Dartmouth College Conference** এ।
এই কনফারেন্সে **John McCarthy, Marvin Minsky, Herbert Simon, Allen Newell** প্রমুখ বিজ্ঞানীরা একত্রিত হয়ে ঘোষণা দেন:
> “Machines can be made to simulate any aspect of human intelligence.” [যন্ত্রগুলোকে মানুষের বুদ্ধিমত্তার যেকোনো দিক অনুকরণ করতে সক্ষম করা যায়। ]
👉 এখান থেকেই “**Artificial Intelligence(AI)**” শব্দটির আনুষ্ঠানিক সূচনা হয়।
❄️ 5. The AI Winter of the 1970s
AI এর প্রতি তখন অনেক আশা ছিল — সবাই ভাবছিল, অল্প সময়েই মেশিন মানুষ হয়ে যাবে!
কিন্তু বাস্তবে দেখা গেল,
* কম্পিউটারের **processing power** খুব কম,
* ডেটা ও স্টোরেজ সীমিত,
* প্রোগ্রামগুলো খুবই basic।
ফলে গবেষণা থেমে গেল, অনেক প্রজেক্ট বন্ধ হয়ে গেল।
এই সময়টাকেই বলা হয় — **“AI Winter”** (1970s)।
🧩 6. The Expert Systems of the 1980s – AI Wakes Up Again!
1980 এর দশকে AI আবার ফিরে এলো **Expert System** নামে।
👉 এগুলো এমন প্রোগ্রাম যা নির্দিষ্ট একটি ক্ষেত্রের বিশেষজ্ঞের মতো সিদ্ধান্ত নিতে পারত।
**Example:**
* **MYCIN:** রোগ নির্ণয় ও ওষুধ পরামর্শে সাহায্য করত।
* **DENDRAL:** রাসায়নিক যৌগ বিশ্লেষণ করত।
এই সময়েই কোম্পানিগুলো বুঝতে শুরু করল, AI **business**, **medicine**, এবং **industry** তে ব্যবহার করা সম্ভব।
🚀 **7. The Skipped Journey to Present-day AI
1990 থেকে আজ পর্যন্ত AI ক্রমশ আরও শক্তিশালী হয়েছে —
* **1997:** IBM-এর **Deep Blue** বিশ্ব চ্যাম্পিয়ন **Garry Kasparov**-কে হারায়।
* **2011:** **IBM Watson** “Jeopardy” গেমে জিতে যায়।
* **2016:** Google DeepMind-এর **AlphaGo** বিশ্বের সেরা Go প্লেয়ারকে হারায়।
* **Now (2020s):** AI আমাদের মোবাইল, গাড়ি, শিক্ষা, চিকিৎসা—সবখানেই!
* ChatGPT (NLP)
* Self-driving Cars (Computer Vision + Reinforcement Learning)
* Medical Diagnosis Systems
🔎 8. Distinction Between AI, Pattern Recognition, and Machine Learning
| Term | Definition | Explanation |
| **Artificial Intelligence (AI)** | The broad concept of machines mimicking human intelligence. | AI হলো মূল ধারণা — মেশিন যেন মানুষের মতো **বুদ্ধি খাটাতে পারে** |
| **Machine Learning (ML)** | A subset of AI where machines learn from data. | ML হলো AI-এর অংশ — মেশিন **data দেখে শেখে** এবং অভিজ্ঞতা থেকে উন্নতি করে। |
| **Pattern Recognition (PR)** | Recognizing regularities or patterns in data (image, sound, text). | PR মানে data এর মধ্যে **pattern বা ধরণ চিনে ফেলা**, যেমন মুখ, শব্দ বা লেখার ধরন। | |
👉 সম্পর্কটা এইরকম ভাবা যায়:
> **Pattern Recognition ⊂ Machine Learning ⊂ Artificial Intelligence**
Key Capabilities of AI:
- Learning (Machine Learning)
- Reasoning and Problem Solving
- Perception (Vision, Speech)
- Language Understanding (NLP)
- Decision Making
Scope of AI:
- 🏥 Healthcare: Disease prediction, robotic surgery
- 🚗 Transportation: Self-driving cars
- 🏫 Education: Personalized learning tools
- 🏢 Business: Chatbots, automation
- 🎮 Entertainment: Game AI, recommendation systems
🔵 Differentiating AI from Human Intelligence
(এআই (AI)এবং মানুষের (Human)বুদ্ধিমত্তার(Intelligent) মধ্যে পার্থক্য)
এআই এবং মানুষের বুদ্ধিমত্তার মধ্যে অনেক পার্থক্য রয়েছে। মানুষের বুদ্ধিমত্তা হলো জটিল এবং বহুমুখী, যার মধ্যে রয়েছে:
* সচেতনতা
* বোঝাপড়া
* যুক্তি
* আবেগ
অন্যদিকে, এআই হলো একটি মেশিন যা মানুষের মতো বুদ্ধিমত্তা প্রদান করার জন্য ডিজাইন করা হয়েছে, কিন্তু এটির সচেতনতা বা আবেগ নেই। এআই এর কাজ হলো নির্দিষ্ট কাজ সম্পাদন করা, যেমন:
* ডেটা বিশ্লেষণ করা
* ছবি চিনতে পারা
* ভাষা বোঝা
উদাহরণ:
মানুষের বুদ্ধিমত্তা: একজন ছাত্র একটি গাণিতিক সমস্যা সমাধান করতে পারে কারণ সে গণিত বোঝে এবং যুক্তি দিতে পারে।
এআই: একটি কম্পিউটার প্রোগ্রাম একটি গাণিতিক সমস্যা সমাধান করতে পারে কারণ এটি প্রোগ্রাম করা হয়েছে এবং ডেটা প্রক্রিয়া করতে পারে।
✅ AI-এর সুবিধা (Advantages of AI)
- দ্রুততা ও দক্ষতা (Speed & Efficiency):
AI অনেক দ্রুত কাজ করতে পারে, যেমন—ডেটা বিশ্লেষণ, রিপোর্ট তৈরি, বা অটোমেটেড উত্তর দেওয়া। - মানব-ভুল কমানো (Reduced Human Error):
নির্দিষ্ট নিয়মে কাজ করলে AI ভুল কম করে, যেমন—স্বয়ংক্রিয় হিসাব বা মেডিকেল ডায়াগনসিস। - ২৪/৭ কাজ করার ক্ষমতা (No Fatigue):
AI ক্লান্ত হয় না, তাই সারাক্ষণ কাজ করতে পারে—যেমন চ্যাটবট বা সার্ভার মনিটরিং। - বিপজ্জনক কাজের জন্য উপযোগী (Risk Handling):
যেমন—স্পেস এক্সপ্লোরেশন, নিউক্লিয়ার রিঅ্যাক্টর পর্যবেক্ষণ, বা মাইন খোঁজা। - ব্যক্তিগতকরণ (Personalization):
Netflix বা YouTube-এর মতো প্ল্যাটফর্মে AI তোমার পছন্দ অনুযায়ী কনটেন্ট সাজায়। - ডেটা বিশ্লেষণ ও সিদ্ধান্ত গ্রহণ (Data Analysis & Decision Making):
AI বড় ডেটাসেট থেকে ট্রেন্ড বের করে সিদ্ধান্ত নিতে সাহায্য করে—ব্যবসা বা স্বাস্থ্য ক্ষেত্রে।
⚠️ AI-এর সীমাবদ্ধতা (Limitations of AI)
- চাকরি হারানোর আশঙ্কা (Job Displacement):
অনেক রুটিন কাজ AI করলে মানুষ চাকরি হারাতে পারে—যেমন কল সেন্টার, ডেটা এন্ট্রি। - উচ্চ খরচ (High Cost):
AI তৈরি ও রক্ষণাবেক্ষণ ব্যয়বহুল—বিশেষ করে ছোট প্রতিষ্ঠানের জন্য। - নৈতিকতা ও গোপনীয়তা (Ethical & Privacy Concerns):
AI যদি ভুল সিদ্ধান্ত নেয় বা ব্যক্তিগত তথ্য ফাঁস করে, তাহলে বড় সমস্যা হতে পারে। - নির্ভরতা ও নিয়ন্ত্রণের অভাব (Over-dependence & Control):
মানুষ যদি AI-এর উপর অতিরিক্ত নির্ভর করে, তাহলে নিজের চিন্তাশক্তি কমে যেতে পারে। - সৃজনশীলতার অভাব (Lack of Creativity & Emotion):
AI আবেগ বা নৈতিকতা বোঝে না, তাই মানবিক সিদ্ধান্ত নিতে পারে না।
AI Subfields and Technologies
মেশিন লার্নিং(Machine Learning)
Machine Learning হলো এমন একটি AI টেকনোলজি যেখানে মেশিন **ডেটা থেকে শিখে নিজের সিদ্ধান্ত নিজে নিতে শেখে, প্রোগ্রামারকে বারবার নির্দেশ না দিয়েও।
উদাহরণ:
* Gmail spam mail চেনা
* Netflix এ movie suggestion
* Credit card fraud detection
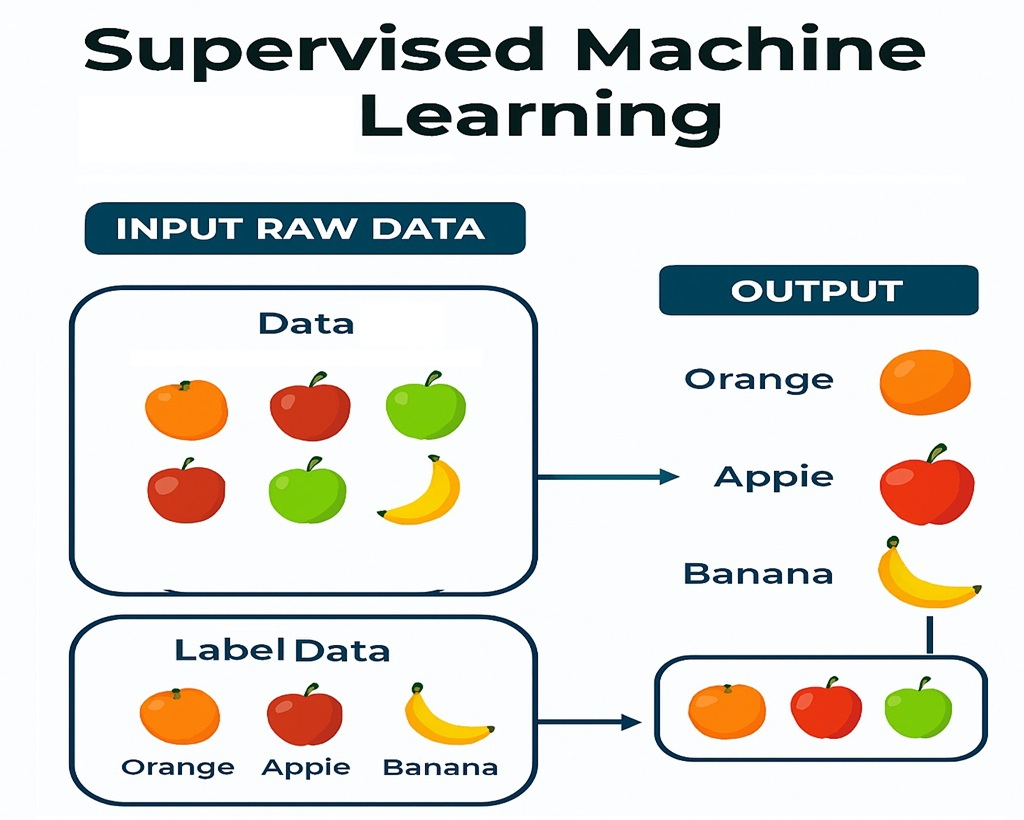
সুপারভাইজড লার্নিং(Supervised Learning): এই প্রকার লার্নিং এ, মেশিনকে লেবেলযুক্ত ডেটা দেওয়া হয় এবং মেশিনকে সেই ডেটা থেকে শিখতে বলা হয়। উদাহরণস্বরূপ, একটি মেশিনকে ছবি চিনতে শেখানো হলে, মেশিনকে লেবেলযুক্ত ছবি দেওয়া হয় এবং মেশিনকে সেই ছবিগুলিকে চিনতে শেখানো হয়।
উদাহরণ: রিয়েল-লাইফ Example: Email Spam Filtering
· Training Data: অনেকগুলো email, যার প্রতিটিতে label করা আছে “spam” নাকি “not spam”।
· Learning Process: Algorithm টি শিখে নেয় কোন words বা patterns দেখলে email টি spam হয় (যেমন: “win money”, “free offer”)।
· Prediction: নতুন email এলে, model টি তার content দেখে predict করে এটি spam নাকি not spam।
অন্যান্য Examples:
· House Price Prediction
· Image Classification (ছবিতে “cat” নাকি “dog” চেনা)
কিছু অ্যালগরিদমের মধ্যে রয়েছে Linear regression, Logistic regression, Random Forest, and other.

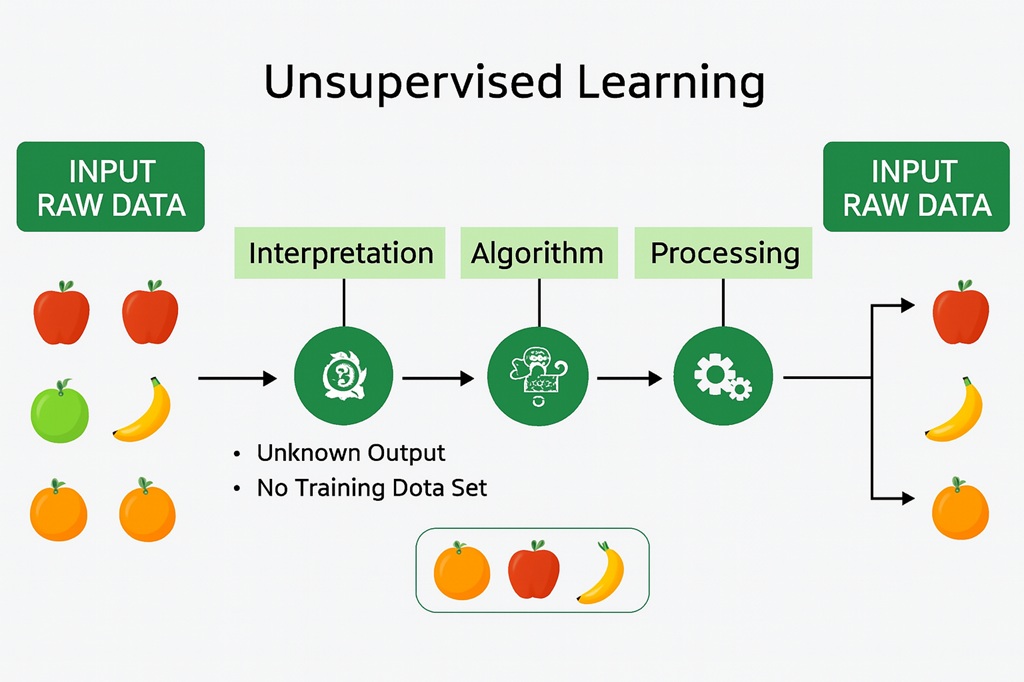
আনসুপারভাইজড লার্নিং(Unsupervised Learning): এই প্রকার লার্নিং এ, মেশিনকে লেবেলহীন ডেটা দেওয়া হয় এবং মেশিনকে সেই ডেটা থেকে শিখতে বলা হয়। তিন ধরণের Unsupervised Learning এর কাজ রয়েছে যার মধ্যে – clustering, association rule, and dimensionality reduction.
উদাহরণ: একটি box-এ mixed ফল (আপেল, কমলা, কলা) দিয়ে সেগুলো similarity (রং, আকার) অনুযায়ী sort করতে বলা।

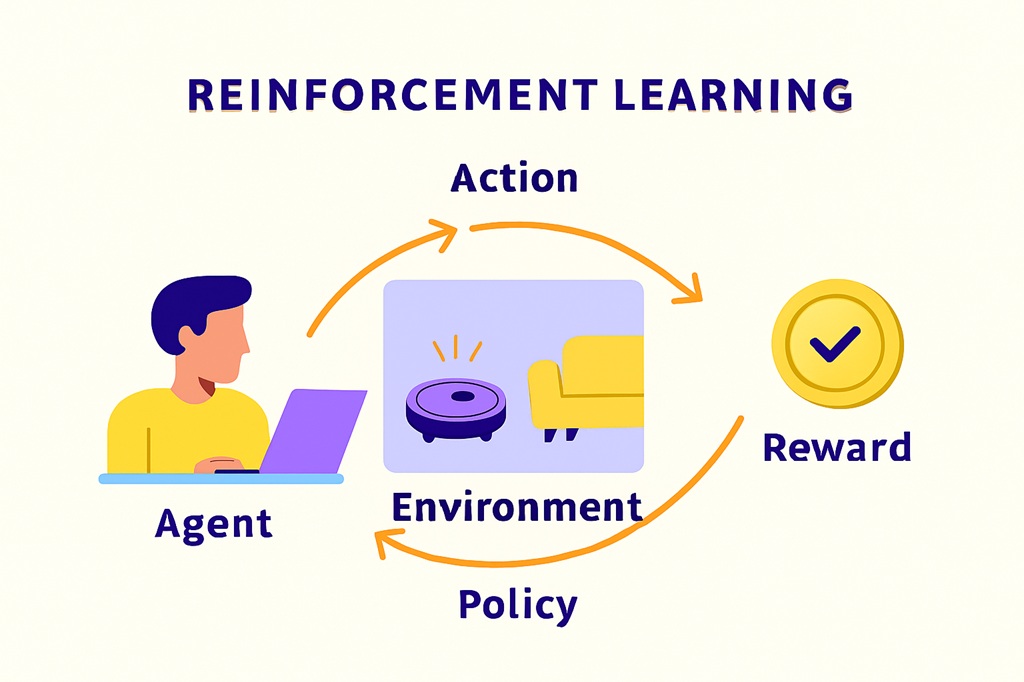
রিইনফোর্সমেন্ট লার্নিং(Reinforcement Learning)**: এই প্রকার লার্নিং এ, মেশিনকে একটি পরিবেশে রাখা হয় এবং মেশিনকে সেই পরিবেশে কাজ করতে শেখানো হয়। মেশিনকে একটি পুরস্কার বা শাস্তি দেওয়া হয় তার কাজের উপর ভিত্তি করে। উদাহরণস্বরূপ, একটি মেশিনকে একটি গেম খেলতে শেখানো হলে, মেশিনকে গেমের পরিবেশে রাখা হয় এবং মেশিনকে গেমটি খেলতে শেখানো হয়।
উদাহরণ: একটি dog কে training দেওয়া। সে সঠিক action (বসা) করলে treat (reward) পায়, ভুল করলে nothing (penalty) পায়।
Real Life Example: Self-Driving Car Training
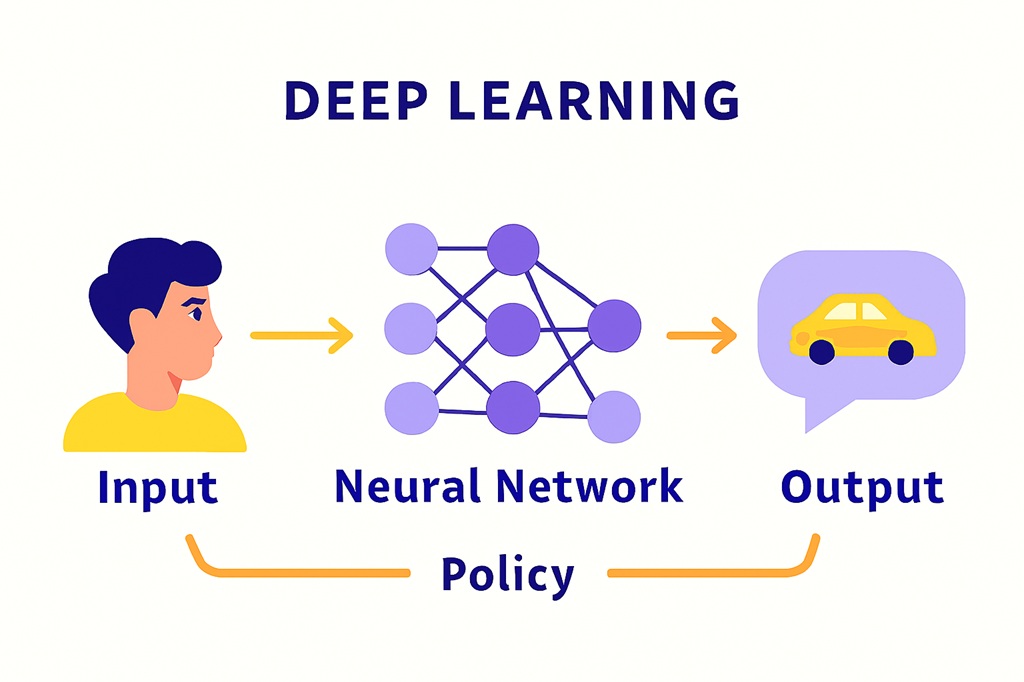
নিউরাল নেটওয়ার্ক(Neural Network) এবং ডিপ লার্নিং(Deep learning)
নিউরাল নেটওয়ার্ক(Neural Network) হল এক ধরনের কম্পিউটার সিস্টেম বা অ্যালগরিদম, যা আমাদের মস্তিষ্কের নিউরন (স্নায়ু কোষ) এবং সিন্যাপসের নেটওয়ার্কের মতো করে তৈরি।
একটি সাধারণ নিউরাল নেটওয়ার্কের তিনটি প্রধান লেয়ার বা স্তর থাকে:
- ইনপুট লেয়ার (Input Layer): এখানে ডেটা বা তথ্য ঢোকে। (যেমন: একটি ছবির পিক্সেল)।
- হিডেন লেয়ার (Hidden Layer): এখানে আসল গণনা বা প্রক্রিয়াকরণ হয়। এই লেয়ার এক বা একাধিক হতে পারে। এখানেই নিউরনগুলো বিভিন্ন গাণিতিক অপারেশন করে প্যাটার্ন শেখে।
- আউটপুট লেয়ার (Output Layer): এখানে চূড়ান্ত ফলাফল বা সিদ্ধান্ত বের হয়। (যেমন: ছবিটিতে “বিড়াল” আছে কিনা)।
ডিপ লার্নিং কি? (What is Deep Learning?)
ডিপ লার্নিং(Deep Learning) হল নিউরাল নেটওয়ার্কের একটি উন্নত এবং বড় সংস্করণ। যখন একটি নিউরাল নেটওয়ার্কে অনেকগুলি হিডেন লেয়ার (Layer) থাকে, তখন তাকে ডিপ নিউরাল নেটওয়ার্ক বলা হয়। আর এই ডিপ নিউরাল নেটওয়ার্ক ব্যবহার করে মেশিনকে যে শেখানো হয়, তাকেই ডিপ লার্নিং বলে।
মূল কথাঃ ডিপ লার্নিং = অনেকগুলো লেয়ার বিশিষ্ট নিউরাল নেটওয়ার্ক।
কেন “ডিপ” বলা হয়?
কারণ এখানেহিডেন লেয়ারগুলোর গভীরতা (Depth) অনেক বেশি হয়। প্রতিটি নতুন লেয়ার আগের লেয়ার থেকে আরও জটিল এবং বিমূর্ত (Abstract) ফিচার বা বৈশিষ্ট্য শেখে।
অনেকগুলো লেয়ারের মাধ্যমে ধাপে ধাপে শেখার কারণে ডিপ লার্নিং(Deep Learning) অত্যন্ত জটিল কাজ, যেমন- স্বয়ংক্রিয় গাড়ি চালানো, মানুষের কথাকে লিখতে রূপান্তর করা (Speech to Text), জটিল গেম খেলা (AlphaGo) ইত্যাদিতে খুবই সফল।
ন্যাচারাল ল্যাংগুয়েজ প্রসেসিং (NLP)
এনএলপি(NLP) হলো এআই এর একটি উপক্ষেত্র যেখানে কম্পিউটারকে মানুষের ভাষা বোঝাতে এবং তৈরি করতে শেখানো হয়।
উদাহরণ: একটি এনএলপি(NLP) মডেলকে একটি প্রশ্নের উত্তর দিতে শেখানো হলে, মডেলটি প্রশ্নটি বোঝে এবং একটি উত্তর তৈরি করে।
কম্পিউটার ভিশন(Computer Vision)
কম্পিউটার ভিশন হলো এআই এর একটি উপক্ষেত্র(Subfield) যেখানে কম্পিউটারকে ছবি এবং ভিডিও বোঝাতে এবং তৈরি করতে শেখানো হয়।
উদাহরণ: একটি কম্পিউটার ভিশন মডেলকে একটি ছবিতে বস্তু চিনতে শেখ
Search as Optimization (only Basic Concepts)
স্টেট স্পেস সার্চ(State Space Search)
স্টেট স্পেস সার্চ হলো একটি প্রক্রিয়া যেখানে একটি সিস্টেমের বিভিন্ন স্টেটগুলি অনুসন্ধান করা হয় একটি নির্দিষ্ট লক্ষ্যে পৌঁছানোর জন্য।
উদাহরণ: একটি রোবটকে একটি নির্দিষ্ট স্থানে পৌঁছানোর জন্য একটি ঘরে অনুসন্ধান করতে হবে।
ডেটা ড্রিভেন(Data Driven) এবং গোল ড্রিভেন সার্চ(Goal Driven Search)
* **ডেটা ড্রিভেন সার্চ(Data Driven)**: এই প্রকার সার্চে, সিস্টেমটি শুধুমাত্র বর্তমান ডেটার উপর ভিত্তি করে অনুসন্ধান করে। এটি কোনও নির্দিষ্ট লক্ষ্য সম্পর্কে জ্ঞান রাখে না।
উদাহরণ: একটি ওয়েব সার্চ ইঞ্জিন ব্যবহারকারীকে একটি নির্দিষ্ট কীওয়ার্ডের উপর ভিত্তি করে ওয়েব পৃষ্ঠাগুলি প্রদর্শন করে।
* **গোল ড্রিভেন সার্চ(Goal Driven)**: এই প্রকার সার্চে, সিস্টেমটি একটি নির্দিষ্ট লক্ষ্য সম্পর্কে জ্ঞান রাখে এবং সেই লক্ষ্যে পৌঁছানোর জন্য অনুসন্ধান করে।
উদাহরণ: একটি রোবটকে একটি নির্দিষ্ট স্থানে পৌঁছানোর জন্য একটি ঘরে অনুসন্ধান করতে হবে।
হিউরিস্টিক সার্চ, ব্রেডথ ফার্স্ট সার্চ(BFS) এবং ডেপথ ফার্স্ট সার্চ(DFS)
* **হিউরিস্টিক সার্চ(Heuristic Search)**: AI সিস্টেমে সমস্যা সমাধানের জন্য হিউরিস্টিক অনুসন্ধান কৌশল ব্যবহার করা হয়। এই কৌশলগুলি একটি শুরু থেকে লক্ষ্য পর্যন্ত সবচেয়ে কার্যকর পথ খুঁজে পেতে সাহায্য করে, যা নেভিগেশন সিস্টেম, গেম খেলা এবং অপ্টিমাইজেশন সমস্যার মতো অ্যাপ্লিকেশনের জন্য এগুলিকে অপরিহার্য করে তোলে।
উদাহরণ: নেভিগেশন সিস্টেম, গেম খেলা এবং অপ্টিমাইজেশন সমস্যার মতো অ্যাপ্লিকেশনের জন্য এগুলিকে অপরিহার্য করে তোলে।
Components of Heuristic Search
- State Space: এর অর্থ হল সমস্ত সম্ভাব্য অবস্থা , যা প্রদত্ত সমস্যার সমাধান হিসাবে বিবেচিত হয়।
- Initial State: সমস্যার প্রাথমিক অবস্থা .
- Goal State: বর্তমান অবস্থা যেখানে সমস্যাটি সমাধান করা হয়েছে।
- Successor Function: এটি এমন একটি পরিস্থিতি তৈরি করে যেখানে পৃথক State গুলি বর্তমান অবস্থাকে প্রতিস্থাপন করে যা সমস্যা স্থানের সম্ভাব্য সমাধানগুলিকে প্রতিনিধিত্ব করে।
- Heuristic Function: একটি হিউরিস্টিকের কাজ হল একটি নির্দিষ্ট অবস্থা থেকে লক্ষ্য অবস্থার মান বা দূরত্ব অনুমান করা।
ব্রেডথ ফার্স্ট সার্চ (BFS): এই প্রকার সার্চে, সিস্টেমটি প্রথমে সমস্ত নোডগুলি অনুসন্ধান করে যা বর্তমান নোডের সাথে সংযুক্ত।
উদাহরণ: একটি সোশ্যাল নেটওয়ার্কে, একজন ব্যবহারকারীর বন্ধুদের তালিকা ব্রেডথ ফার্স্ট সার্চ ব্যবহার করে তৈরি করা যেতে পারে।
ডেপথ ফার্স্ট সার্চ (DFS): এই প্রকার সার্চে, সিস্টেমটি একটি নোড থেকে শুরু করে যতদূর সম্ভব অনুসন্ধান করে।
উদাহরণ: একটি ওয়েব ক্রলার একটি ওয়েব পৃষ্ঠা থেকে শুরু করে যতদূর সম্ভব লিংকগুলি অনুসন্ধান করে।
A* সার্চ(A* Search)
A* Search algorithm সম্ভবত সবচেয়ে সুপরিচিত heuristic search algorithm। এটি একটি best-first search ব্যবহার করে এবং একটি প্রদত্ত প্রাথমিক নোড(Initial Node) থেকে একটি লক্ষ্য নোডে(Target Node) সবচেয়ে কম খরচের পথ খুঁজে বের করে। এর একটি হিউরিস্টিক ফাংশন রয়েছে, যা প্রায়শই f(n) = g(n) + h(n) যেখানে g(n): এটি বর্তমান নোড শুরু নোড থেকে n পর্যন্ত খরচ এবং h(n) হল একটি হিউরিস্টিক যা n থেকে লক্ষ্যে সবচেয়ে সস্তা পথের খরচ অনুমান করে।
Application :A* পাথফাইন্ডিং এবং গ্রাফ ট্র্যাভার্সালে ব্যাপকভাবে ব্যবহৃত হয়।
Applications of AI
এআই ফাইন্যান্স শিল্পে বিভিন্ন উপায়ে প্রয়োগ করা হচ্ছে। এর মধ্যে রয়েছে:
ফ্রড ডিটেকশন(Fraud Detection): এআই(AI) অ্যালগরিদমগুলি ব্যাঙ্কিং এবং ফাইন্যান্সিয়াল প্রতিষ্ঠানগুলিতে প্রতারণা শনাক্ত করতে সাহায্য করে। এআই(AI)) সিস্টেমগুলি লেনদেনের ডেটা বিশ্লেষণ করে এবং অস্বাভাবিক প্যাটার্নগুলি শনাক্ত করে যা প্রতারণার ইঙ্গিত দিতে পারে।
উদাহরণ: একটি ব্যাঙ্ক এআই-ভিত্তিক সিস্টেম(AI Base System) ব্যবহার করে ক্রেডিট কার্ড লেনদেনের ডেটা বিশ্লেষণ করে এবং প্রতারণামূলক লেনদেনগুলি শনাক্ত করে।
অ্যালগরিদমিক ট্রেডিং(Algorithmic Trading): এআই অ্যালগরিদমগুলি (AI algorithm) স্টক মার্কেটে ট্রেডিং সিদ্ধান্ত নিতে সাহায্য করে। এআই সিস্টেমগুলি বাজার ডেটা বিশ্লেষণ করে এবং ট্রেডিং সিদ্ধান্ত নেয়।
উদাহরণ: একটি হেজ ফান্ড এআই-ভিত্তিক সিস্টেম ব্যবহার করে স্টক মার্কেটের ডেটা বিশ্লেষণ করে এবং ট্রেডিং সিদ্ধান্ত নেয়।
রিস্ক অ্যাসেসমেন্ট(Risk Assessment): এআই অ্যালগরিদমগুলি(AI Algorithm) ফাইন্যান্সিয়াল প্রতিষ্ঠানগুলিতে(Financial Institution) ঝুঁকি মূল্যায়ন করতে সাহায্য করে। এআই সিস্টেমগুলি ডেটা বিশ্লেষণ করে এবং ঝুঁকির সম্ভাবনা শনাক্ত করে।
উদাহরণ: একটি ব্যাঙ্ক এআই-ভিত্তিক সিস্টেম ব্যবহার করে ঋণগ্রহীতাদের ক্রেডিট রেটিং মূল্যায়ন করে এবং ঝুঁকির সম্ভাবনা শনাক্ত করে।
এআই ইন কাস্টমার সার্ভিস এবং চ্যাটবটস(AI in Customer service and Chatbot)
এআই কাস্টমার সার্ভিসে বিভিন্ন উপায়ে প্রয়োগ করা হচ্ছে। এর মধ্যে রয়েছে:
* **চ্যাটবটস**: এআই-ভিত্তিক চ্যাটবটস কাস্টমারদের প্রশ্নের উত্তর দিতে এবং সমস্যা সমাধান করতে সাহায্য করে।
উদাহরণ: একটি কোম্পানি এআই-ভিত্তিক চ্যাটবট ব্যবহার করে কাস্টমারদের প্রশ্নের উত্তর দেয় এবং সমস্যা সমাধান করে।
* **কাস্টমার সার্ভিস অটোমেশন**: এআই অ্যালগরিদমগুলি কাস্টমার সার্ভিস প্রক্রিয়াগুলিকে স্বয়ংক্রিয় করতে সাহায্য করে।
উদাহরণ: একটি কোম্পানি এআই-ভিত্তিক সিস্টেম ব্যবহার করে কাস্টমারদের অভিযোগগুলি স্বয়ংক্রিয়ভাবে সমাধান করে।
**এআই ইন এডুকেশন(AI in Education)**
এআই শিক্ষা শিল্পে বিভিন্ন উপায়ে প্রয়োগ করা হচ্ছে। এর মধ্যে রয়েছে:
* **পারসোনালাইজড লার্নিং(Personalized Learning )**: এআই অ্যালগরিদমগুলি শিক্ষার্থীদের শেখার অভিজ্ঞতাকে ব্যক্তিগতকরণ(Personalized) করতে সাহায্য করে।
উদাহরণ: একটি স্কুল এআই-ভিত্তিক সিস্টেম ব্যবহার করে শিক্ষার্থীদের শেখার অভিজ্ঞতাকে ব্যক্তিগতকরণ করে।
* **ইন্টেলিজেন্ট টিউটরিং সিস্টেমস(Intelligent Tutoring System**: এআই-ভিত্তিক সিস্টেমগুলি শিক্ষার্থীদের ব্যক্তিগতকৃত শিক্ষা প্রদান করে।
উদাহরণ: একটি বিশ্ববিদ্যালয় এআই-ভিত্তিক সিস্টেম ব্যবহার করে শিক্ষার্থীদের ব্যক্তিগতকৃত শিক্ষা প্রদান করে।
Ethical and Social Implications of AI
এআই(AI) এর নৈতিক(Ethics) এবং সামাজিক(Social) প্রভাব
**এআই সিস্টেমে পক্ষপাতিত্ব(Bias) এবং ন্যায্যতা(fairness)**
এআই সিস্টেমগুলি পক্ষপাতমূলক হতে পারে যদি তারা নির্দিষ্ট গোষ্ঠীর প্রতি অন্যায়ভাবে আচরণ করে। এটি বিভিন্ন কারণে হতে পারে, যেমন:
* **ডেটা পক্ষপাতিত্ব(Data Bias)**: এআই সিস্টেমগুলি যে ডেটার উপর প্রশিক্ষিত হয় তা যদি পক্ষপাতমূলক হয়, তাহলে সিস্টেমটিও পক্ষপাতমূলক হবে।
* **অ্যালগরিদমিক পক্ষপাতিত্ব(Algorithmic Bias)**: এআই সিস্টেমের অ্যালগরিদম যদি পক্ষপাতমূলক হয়, তাহলে সিস্টেমটিও পক্ষপাতমূলক হবে।
উদাহরণ: একটি এআই-ভিত্তিক চাকরি নির্বাচন সিস্টেম যদি পুরুষদের প্রতি পক্ষপাতমূলক হয়, তাহলে এটি মহিলাদের চাকরি পাওয়ার সুযোগ কমিয়ে দিতে পারে।
**এআই এর কর্মসংস্থান এবং কর্মশক্তির উপর প্রভাব**
এআই এর আগমনের ফলে কর্মসংস্থান এবং কর্মশক্তির উপর উল্লেখযোগ্য প্রভাব পড়তে পারে। এআই সিস্টেমগুলি কিছু কাজকে স্বয়ংক্রিয় করতে পারে, যা কর্মসংস্থান হারাতে পারে।
উদাহরণ: একটি কোম্পানি এআই-ভিত্তিক সিস্টেম ব্যবহার করে গ্রাহক সেবা প্রদান করে, যা গ্রাহক সেবা কর্মীদের চাকরি হারাতে পারে।
**এআই এবং সামাজিক অসমতা**
এআই এর আগমনের ফলে সামাজিক অসমতা বৃদ্ধি পেতে পারে। এআই সিস্টেমগুলি যদি পক্ষপাতমূলক হয়, তাহলে এটি কিছু গোষ্ঠীর প্রতি অন্যায়ভাবে আচরণ করতে পারে।
উদাহরণ: একটি এআই-ভিত্তিক শিক্ষা সিস্টেম যদি ধনী শিক্ষার্থীদের প্রতি পক্ষপাতমূলক হয়, তাহলে এটি দরিদ্র শিক্ষার্থীদের শিক্ষা গ্রহণের সুযোগ কমিয়ে দিতে পারে।
**এআই এর নৈতিক প্রভাব মোকাবেলা করার উপায়**
এআই এর নৈতিক প্রভাব মোকাবেলা করার জন্য নিম্নলিখিত উপায়গুলি অবলম্বন করা যেতে পারে:
* **এআই সিস্টেমের নকশা এবং বিকাশে নৈতিক বিবেচনা**: এআই সিস্টেমের নকশা এবং বিকাশের সময় নৈতিক বিবেচনা করা উচিত।
* **এআই সিস্টেমের পক্ষপাতিত্ব পরীক্ষা এবং মূল্যায়ন**: এআই সিস্টেমের পক্ষপাতিত্ব পরীক্ষা এবং মূল্যায়ন করা উচিত।
* **এআই সিস্টেমের স্বচ্ছতা এবং জবাবদিহিতা**: এআই সিস্টেমের স্বচ্ছতা এবং জবাবদিহিতা নিশ্চিত করা উচিত।
Know More
Evolution and Genetic Algorithm
Machine Learning-Features & Attribute
Question and Answer
🎓 MCQ Questions
- In machine learning, a hyperplane acts as a ________.
a) Decision boundary
b) Error function
c) Activation function
d) Cost function - হাইপারপ্লেনের সমীকরণ সাধারণত কীভাবে প্রকাশ করা হয়?
a) (y = mx + c)
b)
c)
d)
- মাল্টিপল লিনিয়ার রিগ্রেশনে ওজন ভেক্টর (w) বের করার সূত্র হলো —
a) (w = Xy)
b)
c)
d)
- Hyperplane separates ________.
a) Different classes of data
b) Same class data
c) Random noise
d) Training and testing data - হাইপারপ্লেনের dimension নির্ভর করে —
a) Feature সংখ্যা
b) Label সংখ্যা
c) Error rate
d) Bias term - In 3D space, a hyperplane is represented as a ________.
a) Line
b) Plane
c) Point
d) Curve - নরমাল ইকুয়েশন ব্যবহৃত হয় —
a) ওজন ভেক্টর গণনার জন্য
b) Bias term বাদ দেওয়ার জন্য
c) Error বাড়ানোর জন্য
d) Gradient descent বন্ধ করার জন্য - (X^T) মানে কী?
a) Transpose of X
b) Inverse of X
c) Determinant of X
d) Identity of X - Hyperplane equation in 3D regression is —
a)
b)
c)
d) (ŷ = Xw) - হাইপারপ্লেনের orientation নির্ধারণ করে —
a) Coefficients (
b) Constant term (b)
c) Labels
d) Errors - Position of hyperplane depends on ________.
a) Constant term (b)
b) Coefficients
c) Data points only
d) Gradient - মাল্টিপল লিনিয়ার রিগ্রেশনে লক্ষ্য হলো —
a) Error minimize করা
b) Error maximize করা
c) Bias বাড়ানো
d) Data shuffle করা
a) Feature matrix
b) Target vector
c) Error matrix
d) Bias vector- Hyperplane effectively separates ________.
a) Different classes
b) Same labels
c) Random noise
d) Outliers - Regression model predicts ________.
a) Continuous values
b) Categorical labels
c) Binary outcomes only
d) None - Classification model predicts ________.
a) Labels
b) Continuous numbers
c) Errors
d) Coefficients - হাইপারপ্লেনের সমীকরণে (b) কী বোঝায়?
a) Bias term
b) Weight
c) Feature
d) Error - In SVM, hyperplane is used to ________.
a) Separate classes
b) Merge data
c) Increase error
d) Reduce dimensions - নরমাল ইকুয়েশন ব্যবহার না করে সাধারণত কোন পদ্ধতি ব্যবহার করা হয়?
a) Gradient Descent
b) Random Forest
c) Decision Tree
d) PCA 
a) (X) full rank হয়
b) (X) singular হয়
c) (X) zero matrix হয়
d) (X) diagonal হয়- Hyperplane in 2D is a ________.
a) Line
b) Plane
c) Point
d) Curve - Hyperplane in 1D is a ________.
a) Point
b) Line
c) Plane
d) Volume - Regression model fits data by minimizing ________.
a) Sum of squared errors
b) Sum of absolute errors
c) Sum of bias
d) Sum of weights - হাইপারপ্লেনের equation‑এ (w_i) কী নির্দেশ করে?
a) Feature weight
b) Bias
c) Error
d) Label - (ŷ) কী বোঝায়?
a) Predicted value
b) Actual value
c) Error
d) Bias - নরমাল ইকুয়েশন সরাসরি ওজন বের করে কারণ —
a) এটি analytical solution দেয়
b) এটি iterative নয়
c) এটি gradient descent‑এর বিকল্প
d) সবগুলোই সঠিক - Hyperplane helps in ________.
a) Classification and regression
b) Clustering only
c) Data cleaning
d) Visualization
a) To solve linear equations
b) To find weights analytically
c) To remove bias
d) To normalize data- Regression model‑এর output সাধারণত —
a) Continuous numeric value
b) Binary label
c) Category name
d) Probability - Hyperplane concept is mainly used in ________.
a) Machine Learning
b) Physics
c) Chemistry
d) Literature











Answer
🧩 Details Explanation of Answers
- Decision boundary
👉 Hyperplane হলো সেই রেখা/সমতল যা ডেটাকে আলাদা করে। যেমন স্প্যাম বনাম নন‑স্প্যাম ইমেইল আলাদা করার জন্য একটি সীমারেখা। - (w_1x + w_2y + b = 0)
👉 এটি হলো হাইপারপ্লেনের সাধারণ সমীকরণ। এখানে (w_1, w_2) হলো ওজন, আর (b) হলো bias। - Normal Equation
👉 (w = (X^T X)^{-1} X^T y) সূত্রটি সরাসরি ওজন বের করে। উদাহরণ: বাড়ির দাম পূর্বাভাসে আয়তন, কক্ষ সংখ্যা, অবস্থান স্কোর ব্যবহার করলে এই সূত্রে ওজন বের হয়। - Different classes of data
👉 Hyperplane ডেটাকে শ্রেণীভেদে আলাদা করে। যেমন লাল বিন্দু (Class A) বনাম নীল বিন্দু (Class B)। - Feature সংখ্যা
👉 Dimension নির্ভর করে feature সংখ্যা কত। ২টি feature থাকলে hyperplane একটি রেখা, ৩টি feature থাকলে একটি সমতল। - Plane in 3D
👉 ৩‑মাত্রিক স্থানে hyperplane হলো একটি সমতল পৃষ্ঠ। - ওজন ভেক্টর গণনার জন্য
👉 Normal Equation ব্যবহার করে আমরা প্রতিটি feature‑এর weight পাই। - Transpose of X
👉 (X^T) মানে হলো সারি আর কলাম উল্টে দেওয়া। - 3D regression hyperplane
👉 (w_1x_1 + w_2x_2 + w_3x_3 + b = ŷ) হলো বাড়ির দাম পূর্বাভাসের সমীকরণ। - Coefficients (w_i)
👉 এগুলো plane‑এর ঢাল বা orientation নির্ধারণ করে। - Constant term (b)
👉 এটি plane‑কে উপরে বা নিচে সরায়। - Error minimize করা
👉 Regression‑এর লক্ষ্য হলো predicted value আর actual value‑এর মধ্যে পার্থক্য কমানো। - Feature matrix
👉 (X) হলো ইনপুট ডেটার ম্যাট্রিক্স। যেমন বাড়ির আয়তন, কক্ষ সংখ্যা, অবস্থান স্কোর। - Different classes
👉 Hyperplane বিভিন্ন শ্রেণী আলাদা করে। - Continuous values
👉 Regression আউটপুট দেয় সংখ্যাগত মান (যেমন দাম)। - Labels
👉 Classification আউটপুট দেয় discrete labels (যেমন স্প্যাম/নন‑স্প্যাম)। - Bias term
👉 (b) হলো intercept, যা plane‑কে origin থেকে সরায়। - Separate classes (SVM)
👉 SVM hyperplane ব্যবহার করে শ্রেণী আলাদা করে। - Gradient Descent
👉 Normal Equation না ব্যবহার করলে iterative পদ্ধতি Gradient Descent দিয়ে weight বের করা হয়। - (X) full rank হলে inverse থাকে
👉 কারণ তখন সব feature স্বাধীন থাকে। যদি dependent হয়, inverse থাকে না। - Line in 2D
👉 ২‑মাত্রিক ক্ষেত্রে hyperplane হলো একটি রেখা। - Point in 1D
👉 ১‑মাত্রিক ক্ষেত্রে hyperplane হলো একটি বিন্দু। - Sum of squared errors
👉 Regression এই error minimize করে best fit line/plane বের করে। - Feature weight
👉 (w_i) প্রতিটি feature‑এর প্রভাব নির্দেশ করে। - Predicted value
👉 (ŷ) হলো মডেলের পূর্বাভাস। - সবগুলোই সঠিক
👉 Normal Equation analytical solution দেয়, iterative নয়, gradient descent‑এর বিকল্প। - Classification and regression
👉 Hyperplane উভয় ক্ষেত্রেই ব্যবহৃত হয়। - To find weights analytically
👉 Inverse নেওয়া হয় linear system সমাধান করতে। - Continuous numeric value
👉 Regression output হলো সংখ্যা (যেমন দাম, তাপমাত্রা)। - Machine Learning
👉 Hyperplane হলো ML‑এর মূল ধারণা।
🧠 সহজ উদাহরণ
- Regression: বাড়ির দাম পূর্বাভাস → Continuous value (₹)।
- Classification: ইমেইল স্প্যাম/নন‑স্প্যাম → Label।
- Hyperplane: একটি সমতল যা ডেটাকে আলাদা করে বা trend প্রকাশ করে।
Supervised Learning Details
1. তত্ত্বাবধানে শিক্ষা (Supervised Learning)
Supervised learning একটি মেশিন লার্নিং পদ্ধতি যেখানে মডেলকে লেবেলযুক্ত (labeled) তথ্য দিয়ে প্রশিক্ষণ দেওয়া হয়। যেমন – আমরা শিক্ষককে দেখে শিখি, এখানে শিক্ষকই লেবেল সরবরাহ করেন।
বাস্তব উদাহরণ:
আপনি একটি শিশুকে বিভিন্ন ফল দেখিয়ে নাম শেখাচ্ছেন – “এটা আপেল”, “এটা কলা” – পরে শিশু নতুন ফল দেখে নিজেই বলতে পারে। এটাই supervised learning।
2. রিগ্রেশন (Regression) ও ক্লাসিফিকেশন (Classification)-এর পার্থক্য
| বৈশিষ্ট্য | রিগ্রেশন | ক্লাসিফিকেশন |
|---|---|---|
| আউটপুট | ধারাবাহিক সংখ্যা (continuous value) | শ্রেণি বা ক্যাটাগরি (discrete class) |
| উদাহরণ | দাম, তাপমাত্রা, বয়স অনুমান | ইমেল স্প্যাম কি না, রোগ আছে কি না |
| মডেল আউটপুট | একটি সংখ্যা (যেমন ৪৫০ টাকা) | একটি লেবেল (যেমন “স্প্যাম” বা “নট স্প্যাম”) |
রিগ্রেশনের বাস্তব উদাহরণ:
বাড়ির আকার, লোকেশন, বেডরুম সংখ্যা দেখে তার বিক্রয়মূল্য পূর্বাভাস দেওয়া – এখানে দাম যেকোনো সংখ্যা হতে পারে (৩৫ লক্ষ, ৪২.৫ লক্ষ…)।
ক্লাসিফিকেশনের বাস্তব উদাহরণ:
বৃষ্টির পরিমাণ ও তাপমাত্রা দেখে ভবিষ্যদ্বাণী করা – আজকে “বৃষ্টি হবে” না “বৃষ্টি হবে না” (দুটো মাত্র শ্রেণি)।
3. বাস্তব বিশ্বের কিছু ক্লাসিফিকেশন সমস্যা (Real world classification problems)
- ইমেল স্প্যাম ডিটেকশন – ইনকামিং ইমেলকে “স্প্যাম” বা “ইনবক্স” এ ভাগ করা।
- মেডিকেল ডায়াগনোসিস – রোগীর লক্ষণ দেখে “ডায়াবেটিস আছে” বা “নেই” নির্ণয়।
- ইমেজ রিকগনিশন – একটি ছবিতে “বিড়াল” না “কুকুর” সনাক্তকরণ।
- ক্রেডিট কার্ড জালিয়াতি সনাক্তকরণ – লেনদেনটি “জাল” না “বৈধ”।
- লোন অ্যাপ্রুভাল – ব্যাংক গ্রাহকের তথ্য দেখে “লোন দেবে” বা “দেবে না” – এটি বাইনারি ক্লাসিফিকেশন।
4. লিনিয়ার ক্লাসিফিকেশন (Linear Classification) ও থ্রেশহোল্ড ক্লাসিফায়ার (Threshold Classifier)
লিনিয়ার ক্লাসিফিকেশন
এটি একটি পদ্ধতি যেখানে একটি সরলরেখা (line) বা হাইপারপ্লেন (hyperplane) ব্যবহার করে দুটি শ্রেণিকে আলাদা করা হয়। যেমন – ২D তে একটি সরলরেখা, ৩D তে একটি সমতল।
থ্রেশহোল্ড ক্লাসিফায়ার
এটি একটি নির্দিষ্ট সীমারেখা (threshold) দিয়ে সিদ্ধান্ত নেয় – যদি কোনো স্কোর থ্রেশহোল্ডের উপরে হয় তাহলে একটি শ্রেণি, নিচে হলে অপর শ্রেণি।
বাস্তব উদাহরণ:
মনে করুন, পরীক্ষার নম্বরের ভিত্তিতে student কে “পাস” (1) বা “ফেল” (0) করতে চান।
এখানে একটি লিনিয়ার ক্লাসিফায়ার ব্যবহার করলে:যদি (নম্বর >= 40) -> পাস, else -> ফেল – এখানে থ্রেশহোল্ড হলো 40।
নিচের ছবিটি কল্পনা করুন:
X অক্ষ = পড়ার ঘন্টা, Y অক্ষ = পরীক্ষার নম্বর। লিনিয়ার সেপারেটর একটি রেখা যা পাস এবং ফেল এলাকাকে আলাদা করে। থ্রেশহোল্ড সিদ্ধান্ত নেয় রেখার কোন দিকে কোন শ্রেণি পড়বে।
5. মিসক্লাসিফিকেশন এরর (Misclassification Error) ও অ্যাকিউরেসি (Accuracy)
যখন একটি মডেল ভুলভাবে কোনো ডেটাকে ভুল শ্রেণিতে ফেলে, তখন সেটি মিসক্লাসিফিকেশন।
- মিসক্লাসিফিকেশন এরর রেট = (ভুল পূর্বাভাসের সংখ্যা) / (মোট ডেটা সংখ্যা)
- Accuracy = (সঠিক পূর্বাভাসের সংখ্যা) / (মোট ডেটা সংখ্যা)
অর্থাৎ, Accuracy = 1 – Error Rate
বাস্তব উদাহরণ:
একটি স্প্যাম ডিটেক্টরকে ১০০টি ইমেল দিলাম। সঠিকভাবে ৯২টি ইমেলের শ্রেণি বলতে পারলো, ভুল করলো ৮টিতে। তাহলে –
- Accuracy = 92/100 = 0.92 (92%)
- Misclassification Error = 8/100 = 0.08 (8%)
6. ইনপুট স্পেস (Input Space) ও লিনিয়ার সেপারেটর (Linear Separator)
ইনপুট স্পেস
ডেটার প্রতিটি বৈশিষ্ট্য (feature) অক্ষ হিসেবে চিন্তা করলে যে বহুমাত্রিক জায়গায় ডেটা পয়েন্টগুলো অবস্থান করে, তাকে ইনপুট স্পেস বলে।
উদাহরণ – দুটি বৈশিষ্ট্য থাকলে (যেমন, “বয়স” ও “আয়”) সেটি ২D স্পেস।
লিনিয়ার সেপারেটর
একটি লাইন বা সমতল যা ইনপুট স্পেসকে দুই ভাগে ভাগ করে, যাতে এক ভাগে একটি শ্রেণি এবং অন্য ভাগে দ্বিতীয় শ্রেণি পড়ে। যদি ডেটা এমনভাবে লিনিয়ার সেপারেটর দিয়ে আলাদা করা যায়, তবে তাকে লিনিয়ারলি সেপারেবল বলে।
বাস্তব উদাহরণ:
একটি ব্যাংকের ডেটা: X অক্ষ = “আয়ের পরিমাণ”, Y অক্ষ = “ক্রেডিট স্কোর”।
লোন দেয়ার সিদ্ধান্ত – একটি লিনিয়ার রেখা আঁকা হলো। রেখার উপরের দিকের পয়েন্টগুলো “লোন অনুমোদিত” এবং নিচের দিকেরগুলো “অস্বীকৃত”। এই রেখাটিই লিনিয়ার সেপারেটর। আর যে সমতলে বিন্দুগুলো ছড়িয়ে আছে সেটি ইনপুট স্পেস।
সংক্ষিপ্ত সারাংশ (বাংলায়)
- Supervised learning: লেবেলযুক্ত তথ্য থেকে শেখা।
- Regression: ধারাবাহিক সংখ্যা পূর্বাভাস (যেমন দাম)।
- Classification: শ্রেণি চিহ্নিতকরণ (যেমন স্প্যাম/নট স্প্যাম)।
- Linear classifier: সরলরেখা দিয়ে শ্রেণি বিভাজন।
- Threshold classifier: নির্দিষ্ট সীমার মান তুলনা করে সিদ্ধান্ত (যেমন পাস-ফেলের জন্য ৪০ নম্বর)।
- Misclassification error: ভুল পূর্বাভাসের হার।
- Accuracy: সঠিক পূর্বাভাসের হার।
- Input space: বৈশিষ্ট্যগুলো দ্বারা গঠিত জায়গা।
- Linear separator: সেই জায়গায় আঁকা সরলরেখা/সমতল যা শ্রেণি আলাদা করে।
আশা করি উদাহরণগুলো বিষয়গুলো পরিষ্কার করতে সাহায্য করবে।